
Live Context Retrieval: Grass's Game-Changing Technology for AI
An interview with the co-founder of Grass

Welcome to the alpha please newsletter.

gm friends,
This is a follow up interview with the co-founder of Grass, Andrej Radonjic. We had a killer conversation nine months ago and figured we needed to do a part two, as Grass has become one of the most anticipated Crypto x AI projects in development right now.
Founded with the mission to put control back into the hands of users, Grass has evolved into a powerful network capable of scraping enough data daily to train large language models from scratch.
Grass’s sovereign data rollup will settle on Solana and it will be launching soon.
Key highlights of our conversation include:
Grass's mission to tackle ethical concerns in data collection and usage
The development of Live Context Retrieval (LCR) and its potential to transform AI training and inference
The network's rapid growth and its ability to compete with major tech giants in web crawling
Insights into the upcoming network launch and the decentralization of router infrastructure
The potential for bandwidth monetization and its impact on users
Grass's unique position in servicing both B2B and B2C markets
The shift in AI development focus from scaling to smarter training methods
The role of Grass in the future of AI as models continue to require up-to-date information
*disclosure: I am an early investor in Grass
How would you say the protocol has changed since we last spoke nine months ago? Any updates to the mission, product, or scope?
Our mission has always been to put control back into the hands of users. That hasn't changed, and it never will. We started this project because companies are abusing people’s internet bandwidth by sneaking software into free apps, taking control of IP addresses, and scraping the web at scale. We set out to solve this ethical problem, but along the way, the demand for data exploded, and these ethical concerns grew into much bigger problems.

One major issue is that only two companies in the world are capable of crawling the entire web, and they've built multi-trillion-dollar businesses based on that. You might wonder, 'Why is that a problem?' The answer has to do with live context retrieval. If you're doing anything AI-related—whether you're an enterprise or a user—and you need recent information, but your model wasn’t trained on it, that data has to be retrieved. Right now, those two web crawls are the only ways to do that.
The problem with these web indices is that they’re biassed, the result of two decades of data manipulation. People have been trying to influence search results for 15–20 years, optimising content for advertising. So, when you try to retrieve information for a model in real-time, you first have to filter through all the junk that’s at the top. You can actually see this in a recent paper on ChatGPT, which showed that, in 40% of queries, only 1% of the available data was used. This inefficiency is largely due to the data poisoning that’s been done by these two big companies.
Looking back at our network, we realised that as it grew, we started hitting benchmarks faster than expected. At its current size, our network, Grass, scrapes enough data daily to train ChatGPT from scratch. That’s something we didn’t expect at this stage. And as the network scales, its capabilities grow non-linearly. Right now, with 2.5 million daily active users, Grass can already scrape enough data to train GPT-3.5 from scratch. But if it grows 10–20 times larger, we believe Grass will be capable of crawling the entire web on a daily basis, competing with, or even replacing, those two massive companies.
So, to answer your question, while the scope of our work has expanded, our mission remains the same.
Could you give us an update on where you’re at right now in regards to tackling this mission? What is the bull case for the Grass network going forwards?
In its alpha testing, live context retrieval (LCR) has already shown to be more performant compared to competitors, and from a pricing perspective, there’s no reason to undercut it. The real question is: why would models use Grass as their LCR engine, and why is this so important?
We’re living in a world where the language reasoning capabilities of large models are starting to converge. Many models now offer similar capabilities, so what differentiates them? The answer is their access to information, specifically up-to-date, real-time knowledge. If you think about enterprise use cases for LLMs, nearly all of them require real-time information. It’s hard to imagine a single enterprise pipeline in the coming years that won’t be using LLMs.

Currently, there are only two companies that AI labs can turn to for plugging their models into the internet, which is essentially what LCR does—it gives any LLM online capability. But those companies have their own foundational models. So, why would large AI labs turn to them when they’re direct competitors? Why would they let them see all their API calls? It’s anti-competitive. That’s where Grass comes in. There’s no modular solution out there that isn’t directly competing with its customers, but LCR offers that neutrality.
Additionally, none of the existing solutions are optimised for AI. The current web indices and retrieval mechanisms are heavily poisoned by SEO because they rely on monetization through advertising, with middlemen taking a huge cut. An open web crawl owned by the people can be optimised for AI and made future-first, free from the constraints of ad-based monetization.
Grass offers the only neutral way to connect any model to the internet. We’ve also noticed an interesting trend recently: the focus has shifted from scaling models to making them smarter. This involves improvements at the training level, not just during inference.
Chain-of-thought reasoning has taken off, and models are getting smarter through more effective training processes. What’s particularly interesting is the role of reinforcement learning in this, as it relies on a source of truth. After OpenAI's release of GPT-4, and shortly after DeepMind’s self-correction paper, it became clear that models need to be online during training, not just inference, if they want to be trained to reason properly. This realisation has been extremely interesting.
Can you tell me a bit about how these two different services (inference and training) compare in terms of their value to the business?
So it's unclear which of the two is more valuable long-term from a monetization perspective, because it's unclear how frequently AI labs will be retraining models and having them learn. A lot of these things have to do with how quickly we can get the cost of energy and compute down over the coming years. But as it stands, inference is expected to be the vast majority of it, at least until some of these algorithms get a bit better.
To explain how it works, LCR is a way to retrieve anything from the internet in real time.
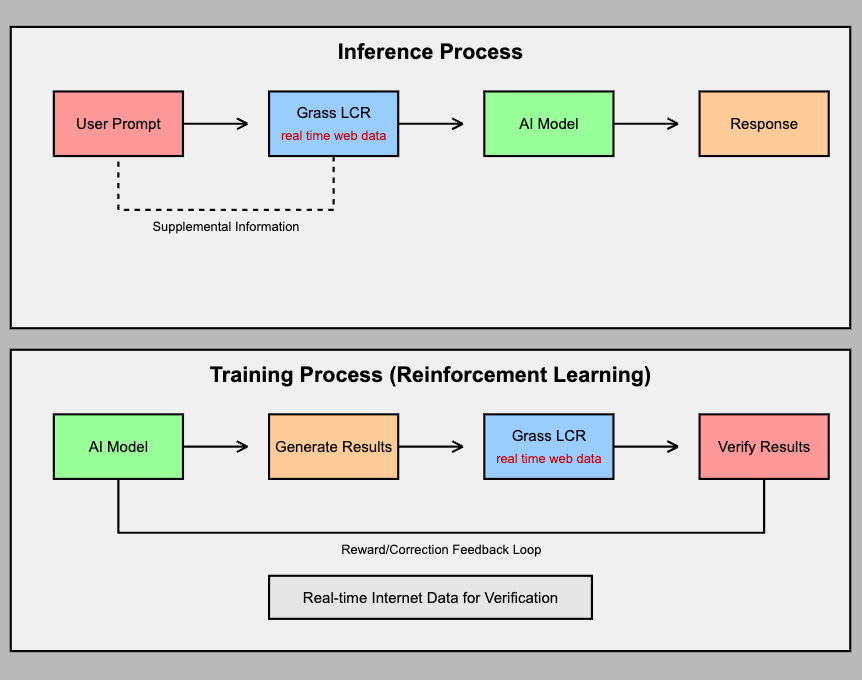
So, you receive a prompt, and it's not necessarily an AI model, but a knowledge graph. Meaning, you send a prompt that's supposed to go to an AI model, and before it hits the AI model, Grass will go and retrieve a bunch of information from the internet to supplement your prompt. Then it hits the AI model, and now this model has all the information it needs to answer your question because a bunch of it came from this LCR process.
That's how it works at the inference level. Now, when you're doing reinforcement learning at the training stage, you're giving it exposure to trillions of tokens of data. In the reinforcement learning process, you're making it generate wrong results and then correct itself. Then you have a reward mechanism for every time it does something properly, and it doesn't receive the reward for doing things incorrectly. It learns from itself by generating information and then verifying it.
Now, that verification stage becomes more difficult if you don't have access to live data. If you want your model to produce some kind of result and then verify whether it was done correctly, you can actually do this much better and on a larger scale if your model is capable of fetching information from the internet in real time to verify its results. What's really exciting about this is that it's undeniable this massively increases the value of a model, but it's so early right now that it's unclear just how big it is.
Are there any more use cases for Live Context Retrieval in the near term?
One of them is with reinforcement learning during the training process, which I mentioned earlier. As far as inference goes, though, a lot of use cases—especially on the enterprise side—have to do with fetching information for competitive analysis and supply chain management. If you're a company managing billions of dollars of goods moving around the world, and you rely heavily on third parties both from a pricing perspective and for monitoring, you actually need to scrape their websites in real time constantly.
A lot of the time, you'll automate these processes with machine learning models to optimise them. When you want to interact with these models, you need real-time information, and LCR plugs into that very well. It's been pretty crazy to see some of the alpha testing results—you can literally retrieve anything from the public web in less than half a second, with virtually zero failure rates.
Could you expand more on the results you've seen from your testing so far?
The way Grass powers LCR is by distributing the fetching of information across millions of nodes around the world, which makes it much faster. These nodes are run on residential devices and networks, which makes the success rate almost 100% because, from a web server's perspective, it's indistinguishable from real user traffic.
The funny thing is, companies are already doing this to people. Any company that needs real-time information from the web is already using people's residential internet connections to spoof those web servers, but they're not paying people for it—and that’s where we take offense. When we build LCR, it becomes a secret ingredient because LCR isn't just about retrieval, it also figures out the context. You can think of it as an unbiased search of the entire internet.
The latency has been incredible, largely because there are so many nodes around the world. One of the things we’re excited about is the decentralisation of routers, which will happen around the time of network launch. With routers more evenly distributed, we’ll be able to run traffic through nodes even faster. For example, if a router is in Japan, it can route traffic through nodes in Japan, instead of having a US-based router route traffic all the way across the world and back.
Right now, with a single router, we’re seeing latency around half a second, and we expect that to come down even further, which is really exciting.
It sounds like the network launch is coming up soon. Can you tell us more about what people can expect after Grass is officially released?
At network launch, the router infrastructure will be in the process of decentralisation. This means the network will go from having a single router to many around the world. Users interacting with the network can delegate their stakes of Grass tokens to these routers if they wish, which will help secure the network as it grows and demand increases. Eventually, bandwidth monetization will be turned on, which we’re pretty excited about.
One thing we've noticed in the community is a bit of short-term thinking, which we understand—many are excited about the first airdrop. But what people need to remember is that the airdrop isn't the point of Grass. The real point is bandwidth monetization, and that hasn't even started yet. From a consumer perspective, that's one of the more interesting things to be excited about.
As for what Grass is doing with bandwidth, LCR will likely transition from alpha to beta testing in the next few months. We’ve also shared some statistics recently about the quantity of multimodal data Grass is scraping. One interesting thing we're seeing is that while the half-life of data is short, it’s not as short for multimodal data. The reason is that many multimodal models haven't yet reached saturation from scaling. A lot of the demand we're seeing relates to multimodal datasets, and we’re excited to share some of those with the world.

From the consumer perspective, this multimodal data is currently enabled by the desktop node, which is really important for the network because it can process much more throughput. The network will be supercharged with the advent of new hardware coming out in the next few months as well, which is something else to look forward to.
Can you tell me about any clients or partners you're working with? What does your pipeline look like in terms of actual customers who'll be using and paying for this data you're collecting?
So, as you can imagine, data is like the gold of the modern age, and every company that wants to make proper decisions needs ridiculous quantities of it. In 99% of cases, data is a company’s competitive advantage, so they don’t want competitors knowing where they’re getting it from. A lot of the agreements being made with the foundation right now are under certain levels of confidentiality, at least as they begin using the network, and over time, they’ll be revealed to the public.
What I can say is that this side of Grass is probably the most exciting thing going on at the moment. Major AI labs are literally using the network right now, and household names—by that, I mean Fortune 500 companies—have been reaching out to the foundation over the last few weeks. It’s interesting because when we set out to build this network, we were told by people who’ve been in the space for a while that, in crypto, it’s easy to bootstrap a huge supply side, but the challenge is convincing companies to add that product to their budget.
However, due to Grass’s unique positioning and the rapid growth of the industry, we’ve actually found the opposite to be true. Scaling the network has been difficult because of the sheer quantity of demand coming in. On any given day, there aren’t enough nodes to service all the inbound demand to the network.

What do you expect revenue to look like after launch?
We can’t say much, but one tidbit I can share is that a big part of why LCR should be exciting to consumers is the tokenomics of Grass. Whenever bandwidth is used to power LCR, Grass tokens are essentially used as gas to power the transaction. So, regardless of whether a client is paying in fiat or crypto (most of the time it's fiat), that fiat needs to be converted into Grass tokens. Tokens have to be bought off the market to facilitate those transactions.
You mentioned a hardware device earlier, could you tell us more about this and the role it plays in the Grass network?
There are many cases where websites need to be scraped that have data that's quite heavy. The hardware device essentially enables anyone to become a power user if they wish. I won’t get into too many details about what's happening under the hood—as exciting as it is—but it will be announced in due time.
The hardware device allows users to contribute to the network in a way that makes it possible to scrape data that’s almost impossible to scrape with the desktop node or the extension. It can do this in more ways and in parallel. It will also be upgradeable, so there are a lot of other things Grass is hoping to do on the edge, and we’re hoping much of that can happen through the hardware device.
You recently had your Series A, which seems to have gone very well. How do you plan to use this capital to push Grass forward?

A lot of the money Grass raised recently will be used toward powering infrastructure. Grass is looking to disrupt an industry that is run by tech giants with near-infinite balance sheets.
It's really important for Grass to achieve its mission, and there’s a tight timeline—a small window—where a lot of these problems can be solved due to how quickly the data industry is moving. The latest round of funding enables Grass to achieve its goals within that window.
Grass is unique in that you’re not only building consumer facing apps with the browser extension and desktop app, but also an entire underlying network infrastructure. How are you tackling these two projects at the same time?
One of the things we believe when it comes to decentralising AI, or decentralisation in general, is that, to a serious extent, crypto has kind of lost its way. In many cases, it’s being used for things it wasn’t meant for in the first place. A big part of this is taking new emerging technologies and forcing crypto into them, saying, 'Okay, this is new and exciting—let’s plug crypto into it and see what happens.'
What you end up seeing is companies decentralising infrastructure and saying, 'Hey, look, we decentralised this,' without asking, 'Why are we decentralising this in the first place? What problem are we solving?'
One of the cool things about Grass is that when we started building, it was immediately obvious that crypto was necessary to solve the problem we were tackling. It wasn’t something where you could just use fiat rails—it would be impossible. You can’t give users network ownership any other way. You can’t build the level of provenance, trust, and transparency any other way. An immutable ledger was necessary, and Grass had to be a crypto protocol.
The point of decentralising, especially AI, should be to benefit users because in most systems, decentralisation introduces technical trade-offs. You’re distributing the system, making it slower, adding peer-to-peer elements, and a certain level of consensus. The trade-off is that, instead of optimising for performance, you’re optimising for fairness. Users are the backbone of AI—they generate the web data that goes into models, and they contribute resources to train them. So, if you’re decentralising anything in the AI stack that isn’t for the net benefit of users, you’re wasting your time. You’re not solving anything.
If you’re building a developer tool that’s decentralised, most of the time you’re not really solving much of a problem. Grass, on the other hand, is building a piece of infrastructure that, through decentralisation, brings control back into the hands of users. It was necessary to have both a B2C-facing silo protocol and a B2B-facing silo protocol, and they require very different messaging and skill sets because the profiles of both parties are so different.
One thing we’ve been lucky with is that, because Grass is solving something so important right now, there’s been a crazy influx of inbound interest from companies. In some cases, it’s for technological reasons—they see that this is a huge network capable of solving what they need. But in many other cases, companies are saying, 'Hey, we’re tired of being unethical. We actually want to do the right thing, and we’re happy that the right solution now exists.' That’s been a really exciting development.
Generally speaking, where do you think AI is today and where do you see it 5 years from now?
I think AI is beginning to have a bit of an identity crisis, and I think that's completely fine. What I mean by an identity crisis is that, a year or two ago, we believed we could take these transformer-based models, scale them infinitely, and achieve endless results with crazy emergent properties. Part of that thinking came from OpenAI’s founders, who kind of gaslit the world into believing it, and also from the sensationalist extrapolation from GPT-2 to GPT-3, where they 100x the data and suddenly there were these emergent properties.
This led to a race to see how we could get to the next emergent property and get models to do even more cool things. In that race, many companies resorted to brute forcing—adding more parameters, data, and compute. Over the last 6 to 12 months, though, we’ve started to see a shift because we realised we were hitting diminishing returns. You can keep making the models bigger, but by the time you reach another emergent property, the company might go bankrupt.
We’re now realising we can achieve the same, if not better, performance by focusing on training these models properly, using the right subset of data and algorithmic changes. The core focus recently has shifted from just adding parameters to making models better at specific tasks, like maths or programming. A big part of that is the 'chain of thought' reasoning that a lot of AI labs are starting to implement.
The other focus is on multimodal data. While brute-forcing has saturated the use of language data, it hasn’t yet with multimodal data. There’s a phenomenon happening in China where hundreds of generative AI video companies are raising money effortlessly, and they’re all looking for multimodal data. This is still relatively short-term—over the next year or two, video models, for example, haven’t exploded in popularity yet, but they will in the next few years.
As for where AI will be five years from now, I’m not even going to try to answer that, because the truth is, I don’t know—and neither does anyone else. I could guess and maybe be right, but it would just be a guess.
What I can say is that two things won’t change: AI models will always need information, and new information will always appear on the internet first. Models will need a way to retrieve information from the internet, and that’s something Grass is uniquely positioned to offer.
Join Grass

And that’s your alpha.
Not financial or tax advice. This newsletter is strictly educational and is not investment advice or a solicitation to buy or sell any assets or to make any financial decisions. Crypto currencies are very risky assets and you can lose all of your money. Do your own research